
Getting Started on RAP
Know Your S3 Path
By Sarthak Rajani
November 13, 2024 | 3 min read
Welcome to RAP! On this platform, every client is setup with their own private AWS S3 location also known as the bucket. Within this bucket, each user has a separate path where their files such as notebooks, CSVs, etc. are stored.
Normally, the S3 path for a user looks like -

This is the root directory that a user can access and work in and this path directs to the user’s Contents drawer.
To know your S3 root path, you can use one of the following methods.
Method 1:
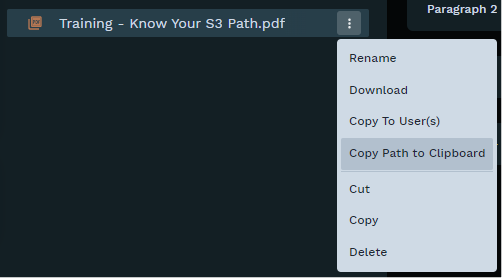
Click on the ellipses (three dots) next to any file in your Contents drawer and select “Copy Path to Clipboard”. This will give you the S3 path for that specific file and will look something like - “s3://bki-rap-client-prod-demo/jupyter/demo_user/Training - Know Your S3 Path.pdf”. You can then trim out the part after your username to get the root path.
Method 2:
Use the following piece of code in a PySpark notebook. It will print out the root path for your account.
import os bucket = os.environ['BUCKET'] username = spark.sparkContext.sparkUser() root_path = 's3://'+bucket+'/jupyter/'+username+'/' print (root_path)
Exporting a CSV to the Contents drawer
To export a dataset as a CSV file, you can use the following piece of code.
df = spark.sql("Input SQL Query")
df.repartition(1).write.options(header='True', delimiter=',').mode('overwrite').csv(“Input CSV Path”)
CSV path refers to the S3 path where you wish to store the file. The S3 path below is shown as an example.
s3://bki-rap-client-prod-demo/jupyter/demo_user/CSV_Folder
Please note:
- The CSV file will be stored inside the folder you specify in your S3 path (“CSV_Folder” here).
- Never input your S3 root path as the CSV path as it will delete all the files present in your Contents drawer.

Sarthak Rajani, Data Scientist
After transitioning from engineering to fintech, Sarthak earned a master’s in quantitative finance from the University of Maryland, College Park. He now excels as a data scientist on the RAP team, bringing profound expertise in data science to drive innovative solutions and strategic insights, along with substantial skills in product specialization and client support.
Related resources
Follow us on Linkedin
Access Mortgage Monitor reports
2025 Borrower Insights Survey report