
RAP Data Science Best Practices
Apache Spark Tips & Tricks
By Lara Parsons
August 16, 2024 | 9 min read
Apache Spark… the queen bee in the hive of data engineering, data science, and data analytics, is the controlling factor in the distribution of work in your RAP notebooks. The behind-the-scenes driver cataloging tasks and assigning executors (i.e., worker bees!) to ensure coding transformations and actions get processed in a cohesive manner. This post aims to outline tips that users new to Spark are often unaware of, and where improving your understanding on the topics will translate directly to improvements in the performance and reliability of your code.
What is Spark?
“Apache Spark is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.” (Apache Software Foundation, n.d.)
“[Spark] has become the leading choice for many business applications in data engineering.” (Grah, 2021)
Spark enables users to work with large-scale, or “Big Data” through a distributed computing framework. Rather than processing bulk data directly on your machine (which requires extensive hardware), it takes the data and divides it (partitions it) across clusters of computer nodes where the processing tasks are computed in parallel, allowing a timelier, and more efficient workflow.
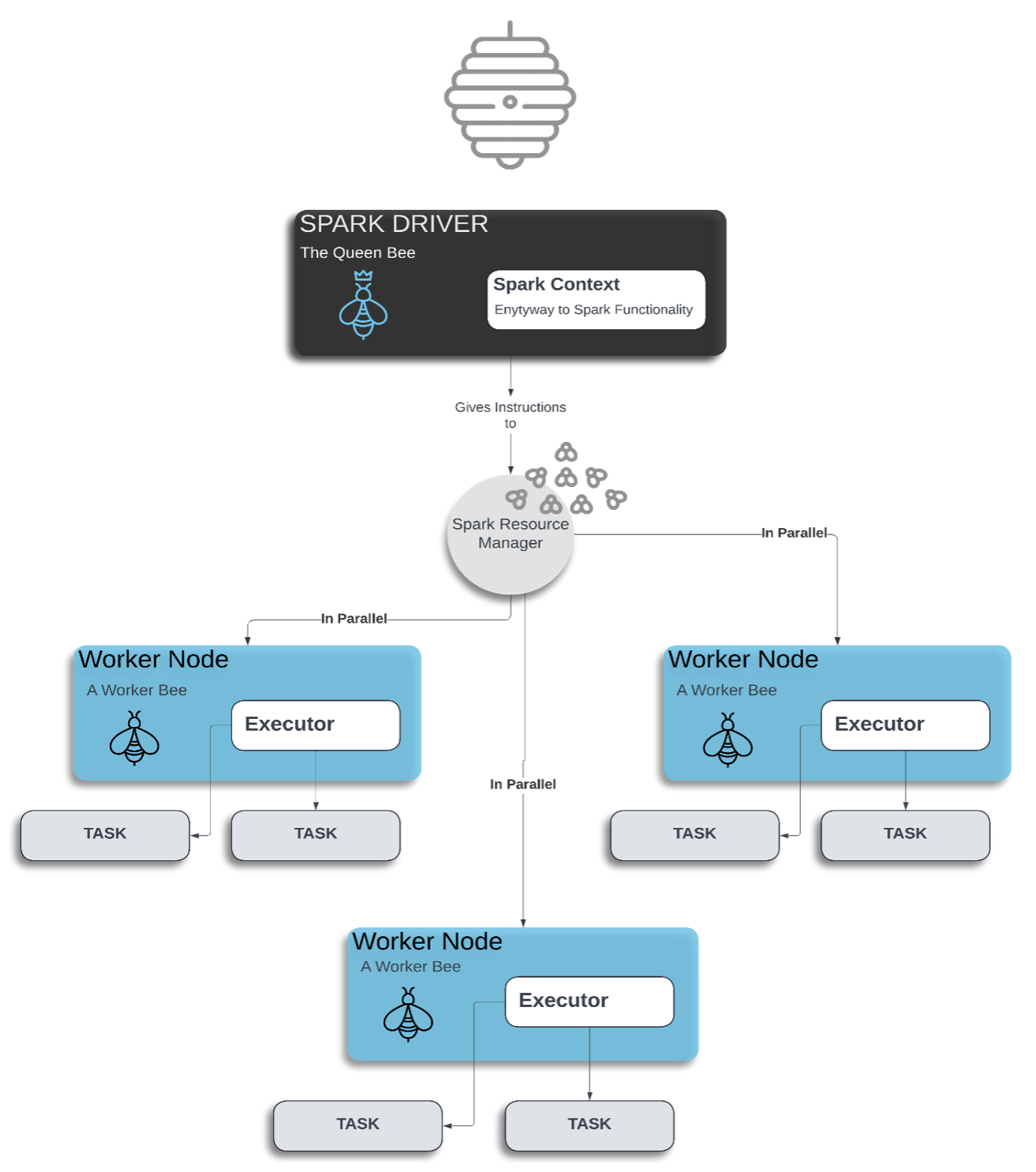
Leveraging Spark’s Parallel Compute
The Rapid Analytics Platform, RAP, is the beekeeper to the Spark hive and allows users to code in multiple programming languages inclusive of SQL, Python, and PySpark, but which of these works in tandem with Spark to leverage its parallel processing capabilities?
Both Spark SQL and PySpark are Spark APIs, or wrappers over the spark framework. Spark SQL allows for coding in (generally) traditional SQL syntax to leverage Spark’s computing methods, while PySpark is a Spark wrapper for the Python language. While PySpark and Python are related languages, they serve different purposes. Python is a general-purpose programming language, while PySpark is built to function on a distributed computing framework. Both are necessary tools for a data scientist to have today and knowing the differences will help determine which is best for your use case.
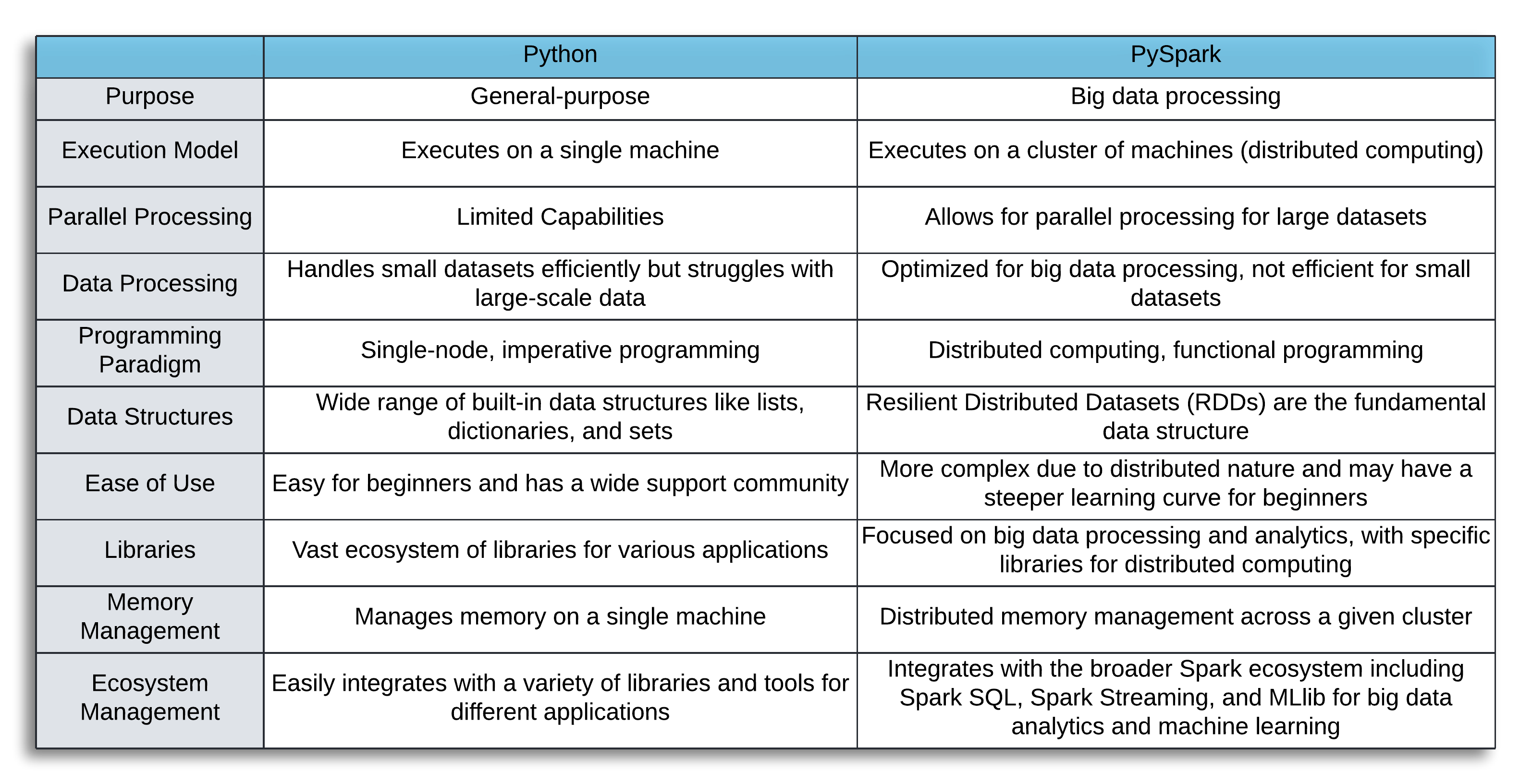
Tip 1:
Know when to utilize Spark’s distributed computing with the PySpark API, and when to use more generalized local Python to reach your programming goals.
In RAP, users should employ PySpark or Spark SQL for ETL (extract, transform, load) on initial data queries, joining, or transforming large mortgage and property datasets. Once your initial large data extracts have been filtered, transformed, and whittled down to the subset of data you wish to analyze it is a good time to switch to local Python coding and leverage the power of the Pandas API, the SK-Learn machine learning library, and plotting libraries like Seaborn or Matplotlib. A good rule of thumb is that if your data is >=~ 2GB locally then PySpark should be your go-to for data transformations. When you are <=~ 2GB locally then you may have improved performance using Python locally.
Though PySpark does have a machine learning library (MLlib) and basic plotting with the Pandas on Spark API, neither are as extensive as those available using local Python so weigh this against the size of your data and your end goals before deciding which route to take. Be aware of what can and cannot be accomplished with Spark and use it to get to meaningful and smaller summaries when possible.
Even with the power of Spark distributed computing, working with big data uses a vast number of resources. Every time you your data is being split up, partitioned, or transformed you want to make sure the code is as efficient as possible. Remember, you can utilize the RAP scheduling function to generate base datasets overnight!
Insight into How Spark Functions
Spark is Lazy
The first thing to keep in mind when working with Spark is that it employs lazy evaluation which allows for improved efficiency and performance. While you are running transformations on data, Spark is in the background building a query plan which only gets triggered when an action is called.
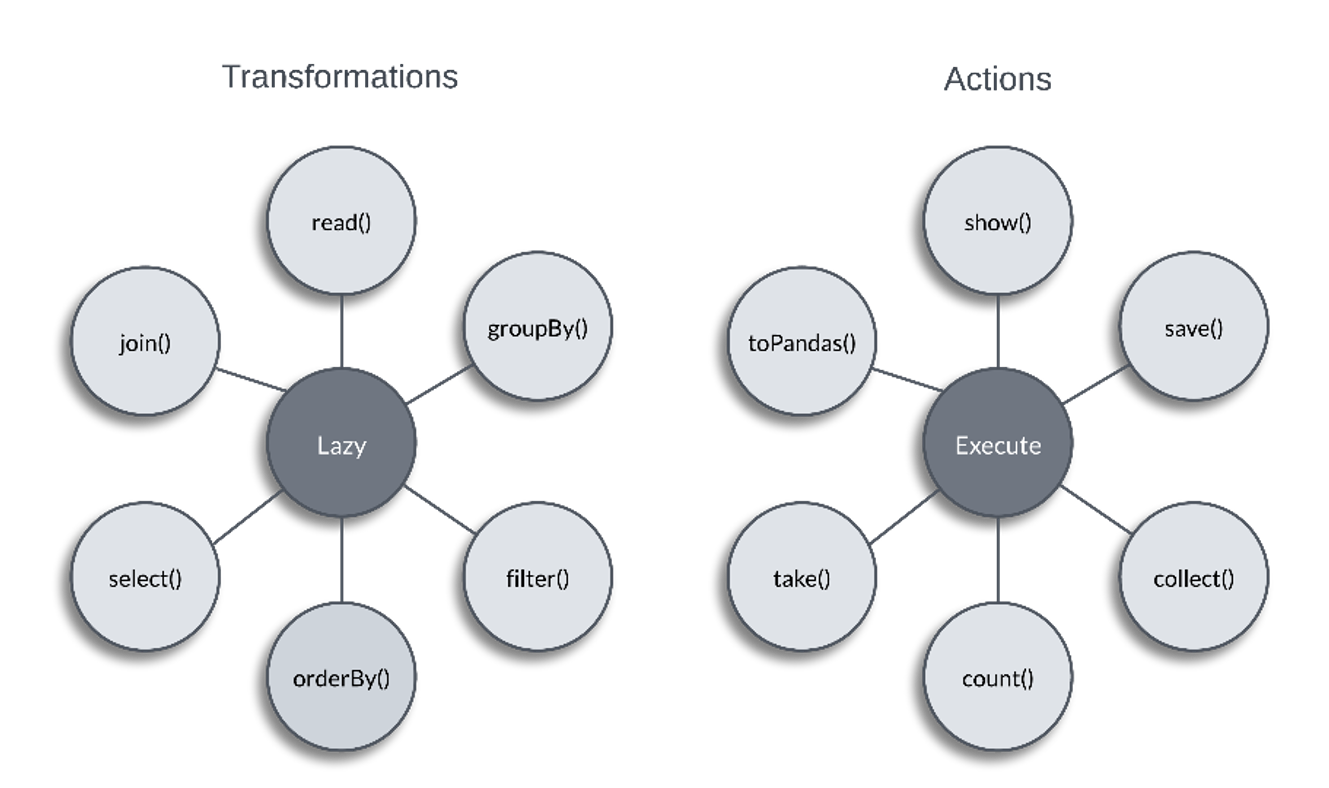
Once the action is called on the data, Spark reviews the query plan of the prior transformations, reorganizes it as needed, and performs the action. Action calls force spark to evaluate and jump to action. If these calls are not needed for the correct functioning of your code let it stay lazy and continue to create an efficient query plan. If action calls are necessary in your programming steps, then look at caching your intermediate results. This allows Spark to skip the tasks leading up to the cached DataFrame when performing further transformations.
Tip 2:
Avoid unnecessary action calls and use intermediate caching or persisting when unavoidable
Spark Likes to Split
Partitions are the name of the game in Spark data storage. To process data in parallel across the multiple executors the data must be chunked into what we call partitions. The partitioning process is generally done when storing (writing) data and is leveraged on future calls to that data. DataFrames can also be repartitioned with the PySpark API based on your current processing needs.
Be aware of the nature of the data transformations you are performing and use Spark partitions to support them.

Tip 3:
Leverage Spark partitioning, especially when applying wide transformations with shuffle operations.
Note: Shuffle discussed in next section
Example:
- DataFrame Columns: [‘state’, ‘zip’, ‘avm_composite’, ‘beds’, ‘living_area’]
- DataFrame Rows: ~119,000,000
- Goal: Group the data by state and calculate the average avm per square foot depending on bedroom size.
- Question: How could partitioning help?
Without Partitioning:
%%pretty
start_time = time.time()
query = '''
SELECT state, zip_code, avm_composite, beds, living_area
FROM ca.avm
'''
avm = spark.sql(query)
avm_gb = avm.groupBy('state', 'beds').agg(
F.round(F.avg(F.col('avm_composite')/F.col('living_area')), 2).alias('avg_avm_per_sqft')
)
avm_gb.show(50, truncate = False)
print(f'Execution Time: {time.time() - start_time}')Execution Time: 32.7081 seconds
With Partitioning:
%%pretty
start_time = time.time()
query = '''
SELECT state, zip_code, avm_composite, beds, living_area
FROM ca.avm
'''
spark.sql(query).repartition(120, 'state').createOrReplaceTempView('avm')
avm = spark.sql('SELECT * FROM avm')
avm_gb = avm.groupBy('state', 'beds').agg(
F.round(F.avg(F.col('avm_composite')/F.col('living_area')), 2).alias('avg_avm_per_sqft')
)
avm_gb.show(50, truncate = False)
print(f'Execution Time: {time.time() - start_time}')
Execution Time: 17.0963 seconds
Spark and the Shuffles
A common challenge in Spark performance is managing transformations that cause data shuffle or moving data from different partitions to the same executor (Lewis, 2024). These types of functions are known as wide transformations. Wide transformations include operations such as joins, grouping, and repartitioning. Narrow transformations generally do not cause shuffling and include things like mapping and filtering.
Shuffle happens because of Spark’s distributed nature and can be antagonized when data is skewed (not evenly distributed), if it is not partitioned in a manner that lends itself to the transformations being performed, or if there is not enough memory on a single note to store all data required for the transformation (R, 2023).
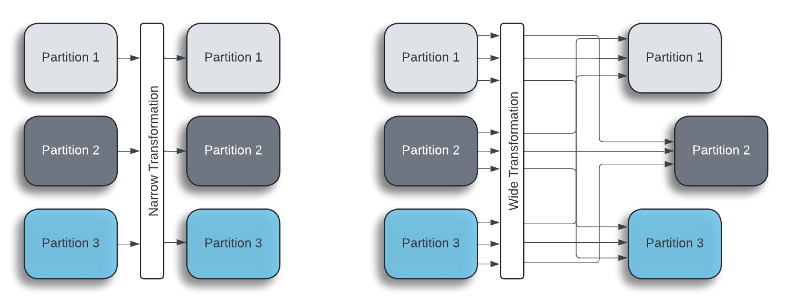
“Shuffle refers to the process of redistributing data across partitions.” (R, 2023)
Shuffling data is the bog in the middle of the field. Not only is it resource costly, but the shuffling must complete before Spark can move to the next stage in its task. Unfortunately, it is unrealistic to say: avoid data shuffle! Well, yes, this would solve your problem, but these functions are common when aggregating data to perform analysis. Instead, let’s say: avoid large shuffle operations when possible, and optimize your data and code syntax for streamlined performance.
Tip 4:
When shuffling data is unavoidable, optimize the underlying DataFrame and transformation code to reduce latency.
Common methods to optimize wide transformations include:
- Leverage Spark partitions. Pre-sorting data based on the fields leveraged in your shuffle-inducing transformations help optimize the process because the data is already co-located across executors and set-up to be processed in parallel (Lewis, 2024).
- Reduce number of columns and filter rows to get down to only the data you need. If you decrease the number of columns and rows initially, there is less data that need to be shuffled around the partitions.
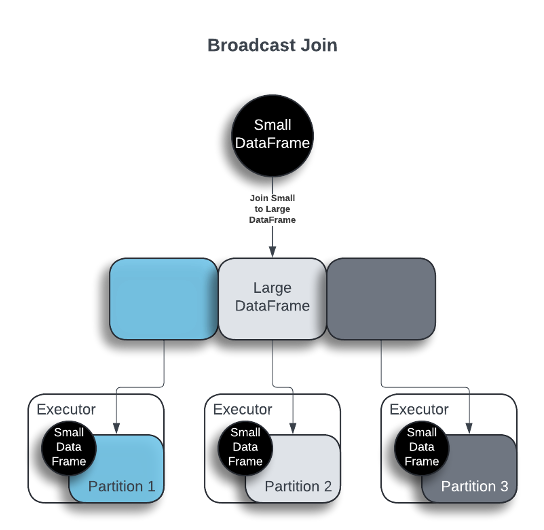
- Utilize broadcast joins. Broadcast joins work when one dataset is small enough to fit onto each executor housing a partition of a large dataset.
- Avoid data skew. Data should be evenly distributed across the nodes, especially when performing joins. Methods to help with data skew include repartitioning in a more evenly distributed manner, salting the partition key, or splitting off the skewed partitions and handling those separately from the rest of the data.
Lend a Helping Hand
If Spark is dividing and managing our programmatic workflows, how can we help it to maximize efficiency? From optimizing your code to avoiding shuffle operations, there are numerous paths towards maximizing parallelism and minimizing processing time with Spark. This article briefly touched on coding methodologies that align with Spark’s computing style, but if you are looking for more in-depth information both the Apache Spark documentation and Medium are good sources.
Good luck in your Spark journey!
References
- Apache Software Foundation. (n.d.). Unified Engine for Large-Scale Data Analytics. Retrieved Aug 8, 2024, from Apache Spark: https://spark.apache.org
- Grah, S. (2021, Nov 24). 6 Recommendations for Optimizing a Spark Job. (Medium) Retrieved Aug 8, 2024, from Towards Data Science: https://towardsdatascience.com/6-recommendations-for-optimizing-a-spark-job-5899ec269b4b
- Lewis, O. (2024, May 14). Taming the Spark Shuffle. Retrieved from Medium: https://medium.com/@ofili/taming-the-spark-shuffle-optimizing-shuffle-operations-in-pyspark-6d0bbd410a36
- R, V. (2023, May 21). Optimizing Apache Spark Performance. Retrieved from Medium: https://medium.com/@vivekjadhavr/optimizing-apache-spark-performance-conquering-data-shuffle-for-efficient-data-processing-fd2f39bce0ce
- Ramesh, V. (2024, Feb 5). Apache Spark + Python = PySpark? Know the DIfferences for Nuilding Data-Based Applications! Retrieved Aug 9, 2024, from Linkedin: https://www.linkedin.com/pulse/apache-spark-python-pyspark-know-differences-building-ramesh-25c0c

Lara Parsons, Data Scientist
Lara has experience in data science disciplines ranging from data engineering, to implementing machine learning models, text mining, and data visualization. She holds a Bachlor of Science in Data Science from Bellevue University and recently transitioned to the RAP product team from the assessor team where she was performing quality checks on the raw property assessment data.
Related resources
Follow us on Linkedin
Access Mortgage Monitor reports
2025 Borrower Insights Survey report